在人工智能领域,一项关于强化学习的新发现正在引起广泛关注。华盛顿大学的一组博士生,通过一项名为Qwen模型的实验,揭示了一个令人惊讶的现象:即使使用错误的奖励信号,RLVR(可验证奖励强化学习)也能显著提升模型的性能,甚至在某些情况下,与真实奖励的效果相差无几。
这一发现彻底打破了人们对RLVR的传统认知。在此之前,人们普遍认为RLVR的优化效果高度依赖于奖励的正确性。然而,华盛顿大学的研究团队却提出了一个反直觉的假设:虚假奖励或许也能在RLVR中发挥积极作用。为了验证这一假设,他们进行了一系列实验。
实验中,团队设计了几种不同的奖励函数来替代标准的真实奖励。这些奖励函数包括多数投票奖励、格式奖励、随机奖励和错误奖励。其中,多数投票奖励是基于模型对训练集的伪标注来设定的,格式奖励则只奖励包含特定格式表达式的响应,随机奖励则完全不考虑回答的正确性,而错误奖励则故意提供错误的监督。实验结果表明,所有这些奖励函数,即使在设计上存在明显的问题,都能在RLVR训练中显著提升模型的数学推理性能。
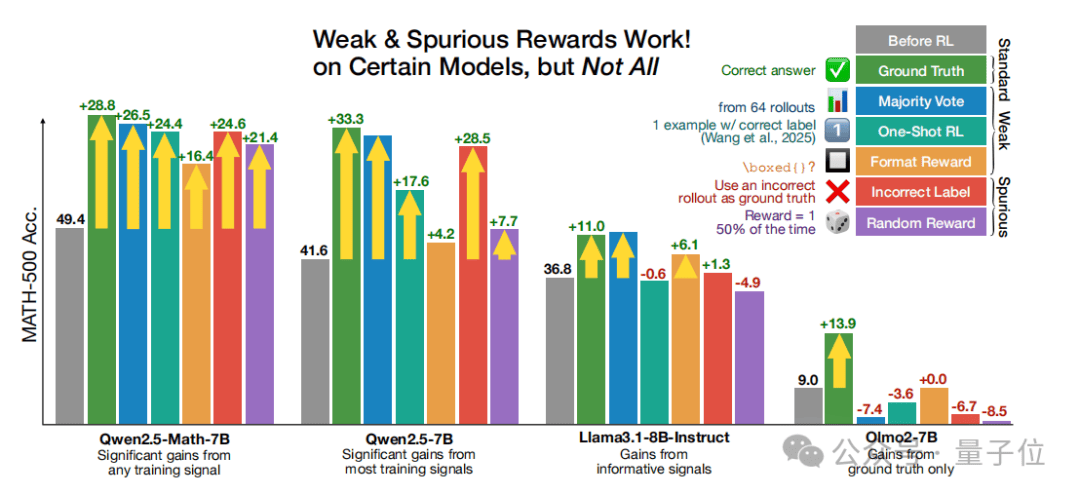
最令人惊讶的是,使用错误奖励进行训练的模型,在MATH500基准测试上的性能提升幅度竟然达到了24.6%,与基于真实答案的RLVR提升幅度(28.8%)相差无几。即使是提供纯噪音的随机奖励,也能带来21.4%的性能提升。这一发现表明,RLVR在提升模型性能时,并不完全依赖于奖励的正确性。
然而,这种奇怪的增益并非适用于所有模型。研究团队发现,只有Qwen2.5系列模型在虚假奖励下能够显著提升性能,而其他非Qwen模型则几乎无变化,甚至还会出现性能下降的趋势。通过分析Qwen2.5-Math-7B和其他模型的推理轨迹,团队找到了问题的关键:预训练期间模型学习到的特定推理策略差异。
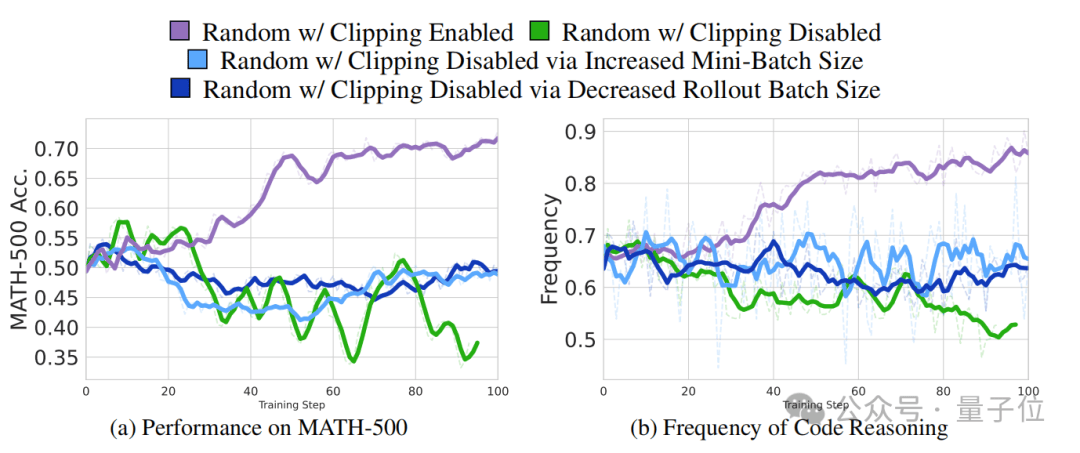
Qwen2.5-Math-7B在推理过程中频繁生成Python代码来辅助思考,尽管这些代码无法执行,但这种代码推理行为与答案准确率高度正相关。而其他模型则没有这种代码推理行为,因此无法从虚假奖励中获益。基于虚假奖励的RLVR还可以有效增强Qwen2.5-Math-7B的代码推理频率,使其在训练初期就迅速提升。

这一发现不仅揭示了RLVR在提升模型性能方面的新机制,还为未来的研究提供了新的思路。研究团队认为,未来的RLVR研究应该更加注重模型在推理过程中的行为,而不仅仅是关注最终的结果。他们也提醒研究人员,不要只盯着单一模型做漂亮数值提升的工作,而应该在不同模型上进行验证,以确保研究结果的普遍性和可靠性。

这项研究不仅展示了RLVR在人工智能领域的巨大潜力,也为我们理解模型的推理过程提供了新的视角。随着研究的深入,我们有理由相信,未来的人工智能模型将更加智能、更加高效,为我们带来更多的便利和惊喜。