国产开源大模型领域近期经历了显著的变革。年初时,业界尚见“AI六小虎”并驾齐驱,而今,仅余寥寥数家仍在牌桌上激烈角逐。在这场激烈的竞争中,DeepSeek凭借其“开源即发布”的策略,加之高性能与高性价比,迅速赢得了用户青睐,并掌握了国产大模型开源叙事的主导权。
DeepSeek的成功,无疑给其他参与者带来了巨大压力。六小虎中的多家公司相继遭遇融资难题、产品更新停滞、团队重组等困境,有的甚至逐渐淡出了公众视线。而DeepSeek所树立的高门槛,也让其他玩家不得不加速布局,以期在市场中占据一席之地。
就在这样的背景下,Kimi团队接棒出击,正式发布了其Kimi K2模型,并选择了开源。Kimi K2分为两个版本:Kimi-K2-Base,一个未经指令微调的基础预训练模型,适合科研与自定义场景;以及Kimi-K2-Instruct,一个通用指令微调版本,擅长处理大多数问答与Agent任务。
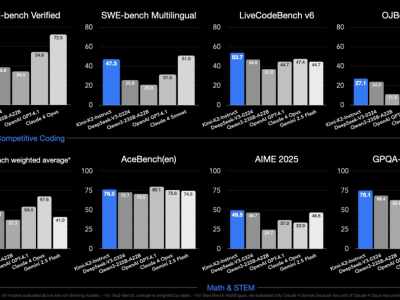
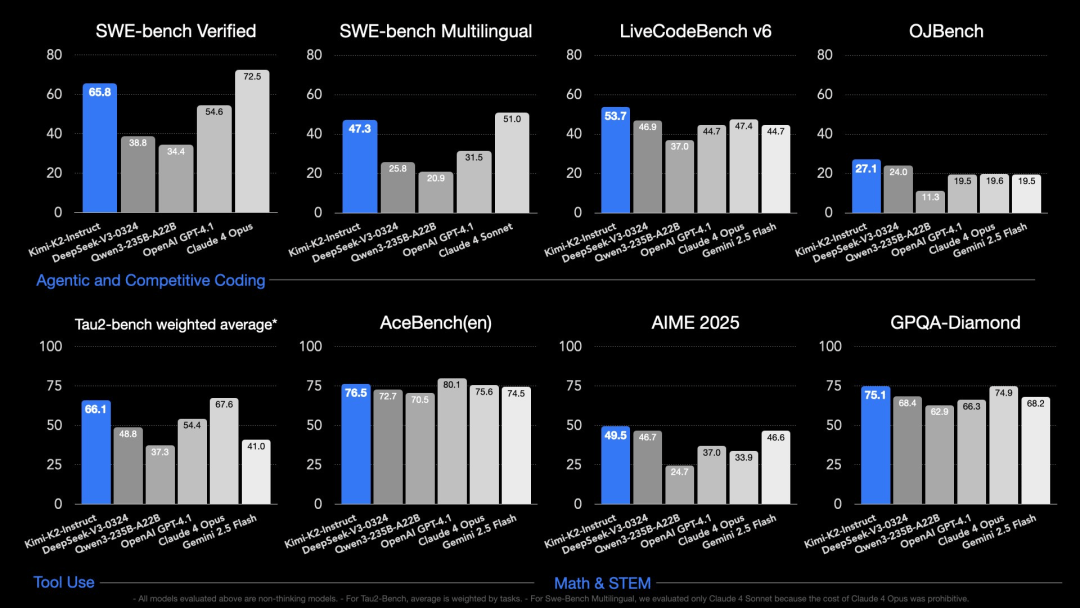
据官方介绍,Kimi K2基于先进的MoE架构设计,参数规模高达1T,激活参数为32B,在代码生成、Agent调度、数学推理等多个任务中展现出强劲竞争力。在SWE Bench Verified、Tau2、AceBench等基准测试中,K2均取得了开源模型中的顶尖成绩,特别是在自主编程、工具调用和数学推理三大能力维度上表现突出。
在实际应用中,Kimi K2在写作能力上的提升尤为显著。例如,在描述一个夏天的午后场景时,K2给出的文本不仅画面感强,而且情绪表达克制、节奏松弛,甚至带有文学色彩。在另一个复杂案例中,要求编写一个看似平淡的“在便利店偶遇前任”的故事,同时隐藏主角身患重病这一副线,K2通过细腻的道具、行为和细节描写,缓缓推进情绪张力,故事结构完整,结尾隐喻巧妙,甚至补上了人物小传,令人惊喜。

然而,Kimi K2也并非尽善尽美。在隐喻密度和句式设计上,K2与DeepSeek存在类似的问题,仍有提升空间。在Agent/Coding任务上,Kimi K2宣称支持ToolCall架构,可无缝接入主流框架,具备自动指令拆解和任务链构建能力。尽管在编程类任务上整体完成度高,但在视觉体验上仍有待加强。
在Kimi K2背后,是Kimi团队自研的一整套技术路径。他们摒弃了传统的Adam优化器,改用自研的Muon体系,并引入MuonClip机制,有效提升了训练稳定性和token使用效率。同时,团队还构建了一条可大规模生成多轮工具使用场景的数据合成pipeline,确保数据质量。在训练策略上,Kimi K2进一步强化了通用强化学习能力,显著增强了模型的泛化能力。
目前,Kimi K2的Instruct模型及FP8权重文件已上传至Hugging Face平台,支持在主流硬件上运行,部署路径已被打通。商业化方面,Kimi K2的API服务也已正式上线,提供最长128K上下文支持,并制定了合理的定价策略。
与Kimi的大方开源相比,OpenAI CEO Sam Altman近期宣布推迟原定下周发布的开放权重模型,理由是需要补充安全测试与高风险区域审查。这一对比,无疑让Kimi的开源举措显得更加开放和自信。